商家评价管理工具
前言
评价是交易链路中最后的一环,也是非常重要的一环,它的重要性体现在为消费者提供了对产品、物流、服务一整套的反馈机制,也为卖家提供了了解消费者的心理,了解自身优劣的丰富内容。而在淘宝上,目前有中国市场最大的消费者反馈信息数据,最为严谨客观公正的评价体系。具备了成为国内最强分析聆听消费者反馈信息的闭环分析能力。虽然还有诸多问题亟待改进,但只要我们合理的规划商家评价管理产品足以帮助到商家供产销服务等环节。在我们产品规划之前,我们对100多位中大型的卖家的评价使用情况,发现即使很多规模较大的商家,仍然在用手工数据导入导出EXCEL分析等“落后”的方式,有很多卖家购买了第三方的工具,有很多ISV在想尽办法爬我们的评价数据。我们工具的初衷,是为了评价领域提供基础的服务能力,为卖家提供闭环的工具,为ISV提供基础服务能力。
产品主要功能:
一.模块1:店铺评价分析
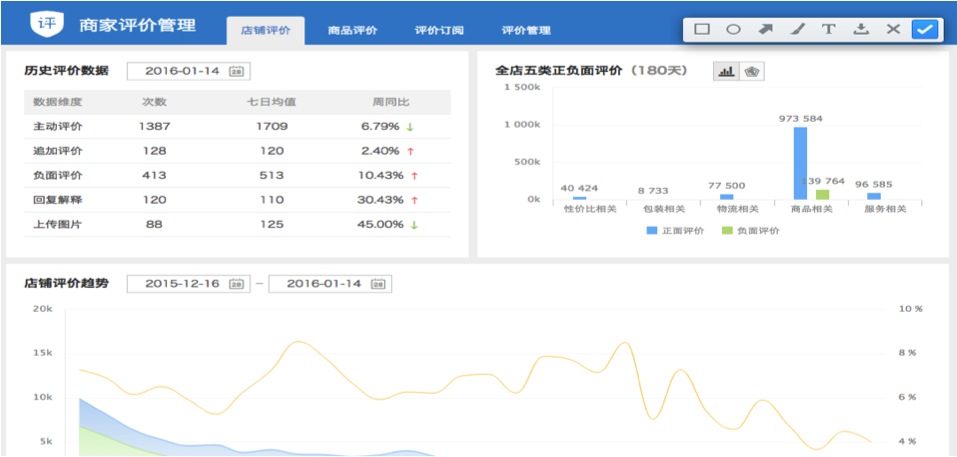
通过对店铺某一时间段的评价数据做统计分析,协助商家快速宏观的了解消费者对店铺的整体反馈情况
1)店铺历史评价数据:每日呈现店铺的主动评价、追加评价、负面评价、回复解释等关键指标,便于商家每日跟踪。
2)最近180天店铺正负面评价情况:对每日的评价内容进行语义分析,按性价比、包装、物流、商品质量、服务5类呈现最近180天正负面汇总及分布,便于卖家了解店铺正负面评价整体情况。
3)店铺评价趋势:最近180天,评价数、主动评价数、传图率的波动
4)店铺DSR趋势:最近180天,店铺DSR的波动及原因分析,帮助卖家跟踪DSR的变化及原因。
二.模块2:商品评价

通过对商品正负面评价的数据分析、文本分析,协助商家查看上架商品在消费者眼中的真实反馈情况。允许卖家按照商品ID、标题、上架时间、DSR分等搜索对应商品的关键指标
三.模块3:评价订阅
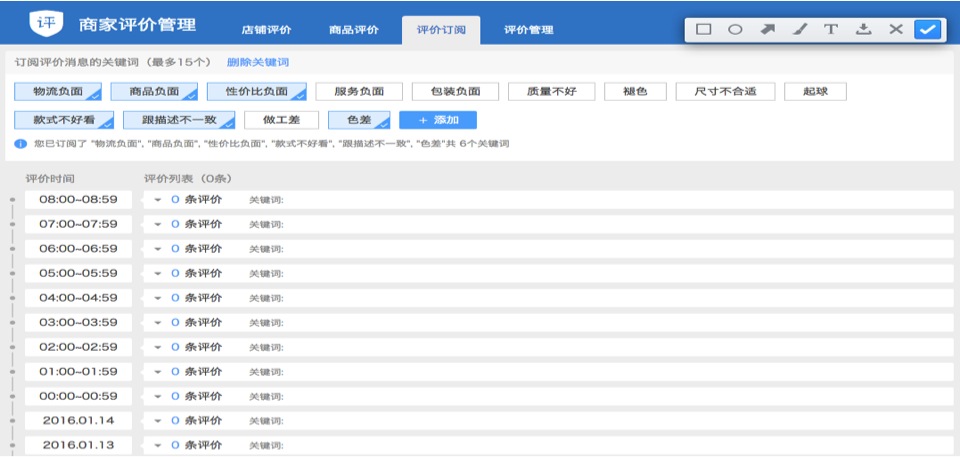
商家可以通过此能力,及时查看自定义关注的消费者评价信息;系统对接了评价的NOTIFY消息,对评价内容进行语义及情感分析,对评价的负面消息按照性价比、包装、物流、商品质量、服务进行分类,允许卖家按类型订阅,并且可以自定义关键词,系统对卖家选择的评价类型或者关键词,匹配对应的评价,准实时地推送给卖家,便于卖家及时了解店铺的消费者的反馈信息,及时处理。
四.模块4:评价管理

对全量的评价内容建索引,帮助卖家按照确定性的信息如:商品ID、订单、买家NICK,或者模糊的信息,如商品标题、关键词查找评价及对应订单,完成日常的评价操作,回复解释、举报评价。
基于评价的基础服务及能力:
基础服务能力,是指我们通过商家评价管理产品,在我们的后台沉淀的基于评价的原子化的能力(包括基础数据、API接口),这些服务可以以数据接口、API服务的方式单独提供给第三方,由第三方直接服务于商家或者做二次加工后包装成其他的产品。
一.店铺及商品维度的评价分析能力

为卖家提供店铺及商品维度的评价关键指标,并可以通过API或者数据表的方式输出给第三方。
二.评价闭环处理能力
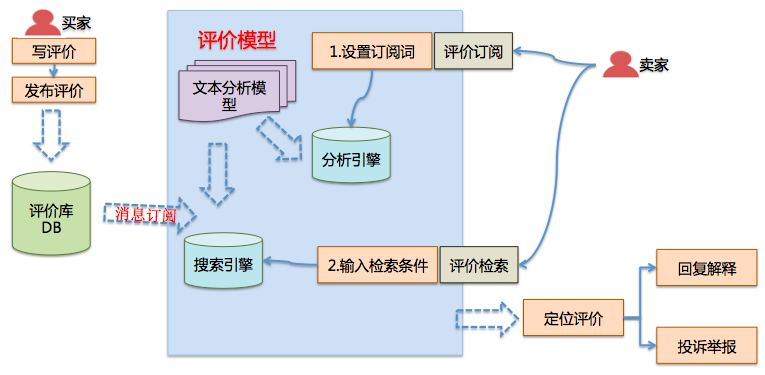
为卖家提供评价的检索及订阅服务,定位评价后,提供评价的反馈、处理能力,如评价回复解释、评价投诉举报等。
三.评价订阅及检索服务
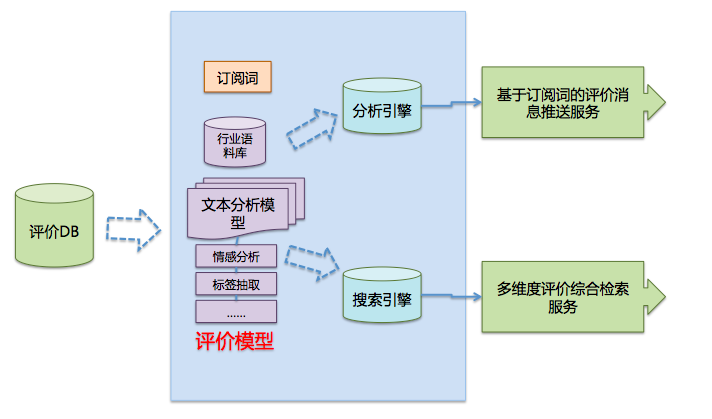
提供最近半年内店铺内评价的全量检索服务,包括按照类目、商品、订单、消费者NICK,时间区间,关键词等多维度综合检索能力,并可以通过API方式输出给第三方。
四.基于评价的文本算法能力
提供基于评价的文本算法能力,包括分词、情感分析、评价标签抽取等,并可以通过API或者数据表的方式输出给第三方,在下一章节《核心算法》中详细介绍。
核心算法
一.评价文本情感分析算法
评价文本情感分析和一般意义上的review sentiment analysis并不是完全一致,因为对于一个影评或者一般的商品评价而言,我们关心的是整体的情感。但是在我们电商体系,尤其是为商家服务时,算法不仅仅要知道整体评价的情感倾向,而更重要的则是评价中对于商品中各个属性的情感倾向,这样来看,这里的评价文本情感分析算法便是一种opinion mining,这个问题就比情感分析更复杂一些。此处,我们只讨论挖掘出属性后,评论人对该属性的情感倾向。
对于情感类问题,英文一般用SentiWordNet,但是中文并没有类似的词典,这个词典只能自己搭建。于此同时,所有处理NLP相关问题时,有一个非常值得重视的问题,就是领域问题。据[刘兵, Sentiment Analysis and Opinion Mining],情感分类对于领域非常敏感,这也符合我们的一般认识,比如:
上午下单下午就收到,物流速度太快了。
一个小时一格电,这个手机的电池用得太快了。
很明显,二者表达的情感完全想反。这里最直接的体现就是,对于不同的属性,相同的情感词的倾向是不一致的。
在情感分析算法中,我们采用分类目词典、适应评价本身的语法规则、当前文本的分类器算法以及上下文GBDT算法进行融合。
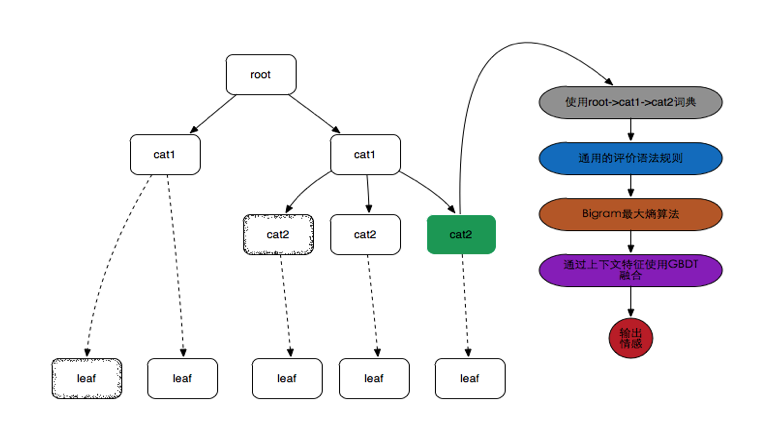
算法框架:
如图,左侧的属性结构是阿里的类目体系,在类目树的节点都可以看做一个领域,在领域内情感的分析是相对准确的,这与常识和实验结论完全一致。
处理业务问题总是先处理重要问题,所以这个构建的类目树中包含一些没有对应词典的节点,而在处理badcase时,这些未构建的词典都是可以人工增加的进行扩展的。
右侧,则是当文本内容对应到类目树上的某个节点时,在该节点下进行分词、规则抽取、Bigram最大熵训练以及上下文特征结合做GBDT融合。
二.评价语义索引算法
评价语义索引体系构建:
非结构化的评价中具有各种各样的结构化信息,每一条评价都会或多或少的表达了买家的观点。
下面分标签提取,标签体系和索引构建三部分说明:
标签提取介绍:
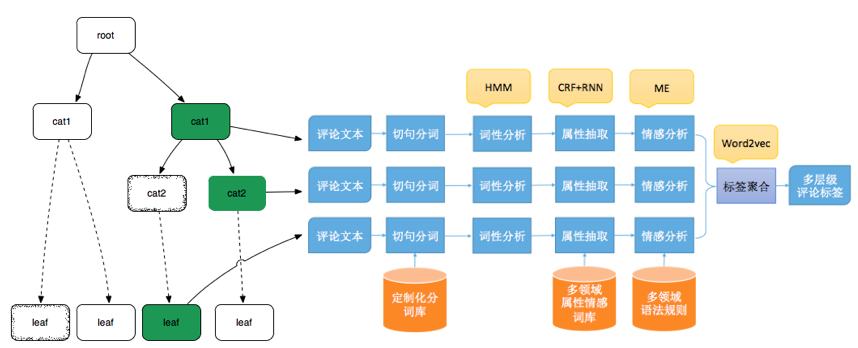
左侧是淘系类目树,每条评价都会根据评价的商品对应到类目树上的一个节点,如果节点的词典没有构建,则回退至其父节点,直至到根节点,该节点是电商领域的通用词典。
右侧是评论文本根据类目树的词典进行分析,词性分析,属性抽取,情感分析和标签聚合。最后构成一个多层级的标签体系。
标签体系介绍
对于标签聚类之后,我们会得到一系列的标签。这些细粒度的标签并不能满足语义搜索的要求。标签还需要进行划分层级以及计算标签之间的关联度,如图:

对于一个一级类目下,会存在上述标签体系,其中有些是全网的骨架,而偏底层的则具有鲜明的类目特点。
这个骨架是由规则控制的,而底层的细粒度标签则是由标签提取算法以及聚类算法发现和归并。
最终体现在标签上是一种后缀结构,对于不同的一级类目,同样的语义我们会给标签相同的后缀。
现在的一个缺陷是,同一个标签其实是可以属于不同的节点,也就是说,上图并非是一个严格的树形结构,而是网型。这部分工作我们做的还不够。
索引构建介绍
传统的索引技术都是倒排索引。这种技术适合NLP领域中one-hot为基础的索引。对于distributed representation,倒排索引技术并不是非常合适。由于工程限制,以及固有标签体系能够满足倒排索引的要求。所以,这里使用的同样是倒排索引技术(使用的是集团内部Vsearch搜索引擎)。
倒排索引如图所示:
其中,这里构建了标签ID和评论词两个维度的posting。而对于标签ID维度,每一个倒排索引检索到的doc能够根据标签本身的层级以及情感过滤出合理的结果。

三.评价订阅词及搜索词(query)理解
Query理解的主要目的是理解用户的搜索行为,对query做变换处理,使用户查询的query映射成为给搜索引擎查询的相关字符串,其主要的算法流程图如图1所示,包括文本预处理、分词与属性识别、同义词扩展、query类别预测、情感预测等五大部分,最终生成类别与情感的查询对,去搜索引擎中查询语义相关的评论。

1)query预处理
Query预处理主要包含以下几个方面:全角半角转换、大小写转换、繁简体转换、纠错、拼音转汉字等等。下面将详细介绍拼音转汉字,可以把这个问题转换为通信问题,即拼音串是接收到的信号,目的是推测出真正的信号,这时就可以使用隐马尔科夫模型。
令y1,y2,y3,y4表示用户输入的拼音,每个拼音对应一个汉字,那么整个拼音串就对应一句话。令w1,w2,w3,w4是用户想要输入的语句,拼音与汉字可以构建如图2的晶格网络,那么现在的问题可以转化为求解:
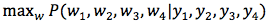
根据贝叶斯公式、条件独立假设和马尔科夫假设,上述问题可以变化为:
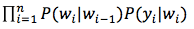
求w(i)使上述公式概率即最大的,如何求最大值,这就需要使用到维特比算法了
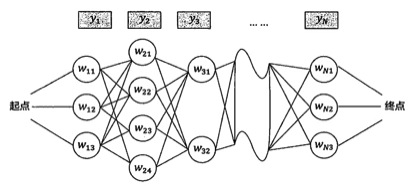
维特比算法的思想很简单,就是假设到达某一个节点的最短路径已经求出并存储在该节点上,那么计算某一层的节点时,只需要计算前一层所有节点到该节点的路径长度加上起点到前一层节点的最短路径中的最小值就是起点到该节点的最短路径。以求第二层节点的最短路径为例,维特比算法可以表示为:

这里表示求第2层第i个节点的最短路径,S表示起点。可以看出求第二层某个节点的最短路径要遍历第一层所有的节点。
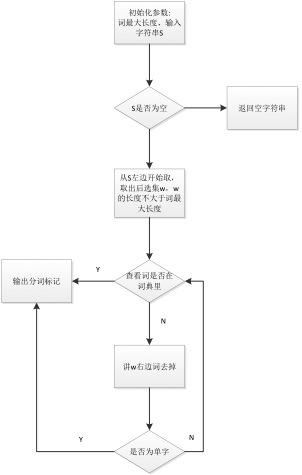
2)分词算法
分词是文本服务的一个基础功能,目前主要是基于词库的分词方法,先通过前向后向最大匹配的方法选出多种切分的候选集,然后通过语言模型来对各种分词的方法进行打分。下面会介绍前向分词的算法流程,主要过程如图所示,会从句子中找出最大词长度的字符串,然后去查找词典,如果查到则为一个词,如果没有找到则把查找字符串的右边去掉一个字,然后再去匹配,直到单字为止。
利用前向后向等多种分词方法对句子切分后,我们需要对切分的效果进行打分,通常是利用语言模型。一个语言模型通常构建为字符串s的概率分布p(s),p(s)试图反映字符串s作为一个句子出现时的频率。与语言学不同,语言模型与句子是否合乎语法没有关系,主要通过词的联合概率分布来判断其是否为一个合法的句子,其概率计算公式为:
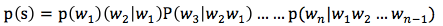
3)同义词扩展
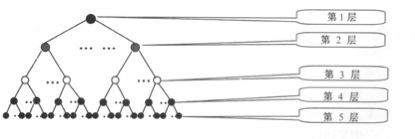
在同义词扩展中,主要由两部分组成,一部分是基于哈工大同义词词林,另外是基于Word2vec的相似度挖掘。哈工大同义词词林按照树状的层次结构把所有收录的词条组织到一起, 把词汇分成大、中、小3类, 大类有12个, 中类有97个, 小类有1 400个。每个小类里都有很多的词, 这些词又根据词义的远近和相关性分成了若干个词群(段落)。每个段落中的词语又进一步分成了若干个行, 同一行的词语要么词义相同(有的词义十分接近), 要么词义有很强的相关性,如图所示:
提出的相似度算法根据同义词词林编排特点,基于同义词词
林结构, 利用词语中义项的编号, 根据两个义项的语义距离, 计算出义项相似度,综合考虑了词语所在树的密度, 分支的多少等,算法如下:

其中,d表示两个词相同的最大树深度,如果相同的深度越大,说明语义上越接近,n表示分支层的节点总数,k表示两个分支间的距离
Word2Vec主要是将每个词映射到一个新的空间中,并以多维的连续实数向量进行表示叫做词向量。自从21世纪以来,人们逐渐从原始的词向量稀疏表示法过渡到现在的低维空间中的密集表示。用稀疏表示法在解决实际问题时经常会遇到维数灾难,并且语义信息无法表示,无法揭示词之间的潜在联系。而采用低维空间表示法,不但解决了维数灾难问题,并且挖掘了词之间的关联属性,从而提高了向量语义上的准确度。Word2Vec模块的引入主要是为了计算词语之间的语义相似度,在词的相似度挖掘中中,主要的用法是首先首先对商品评论进行分词,然后利用Word2vec模型去学习评论中分词后的词向量,最后利用学习到的词向量去做两两相似度关联,获取更多语义相近的属性词。
4)query属性词类别归一
在query属于哪个属性类别的分类,主要使用k-最近邻的分类方法,该算法优点是对于新增类别不需要重新训练模型,实现简单。KNN方法的基本思想是:给定一个query,系统在训练集中查找离它最近的k个属性词,并根据这些紧邻属性词的分类来给该query分类。把邻近属性词和查询query的相似度作为邻近属性所在类别的权重,如果这k个紧邻属性类别的部分属性词属于一个类别,则将该类别中每个紧邻属性词的权重求和,并作为该类别和属性分类的相似度。然后通过对候选分类评分的排序,给出一个阈值,可以用公式表示为:
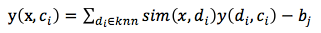
总结&展望
商家评价管理工具自15年11月中旬上线以来,累计了140万的用户,很好地解决了商家日常的评价管理工作中缺乏权威数据,缺乏统一管理平台的问题。解决这个问题只是第一步,目前团队正在做的是,把工具中的一些沉淀(如评价的检索),以原子化的方式提供给其他团队包括ISV,让ISV在我们的原子能力基础上做更多的应用,更好地服务商家。
- <
- 1
- 下一页 >